


Fabric Jobs Flow
Similar to most Fabric entities, a Job's flow undergoes the following stages:
Fabric Jobs Status
All Fabric Jobs undergo different stages, where each stage indicates a specific step in the Job's handling process:
Statuses
Job's Lifecycle
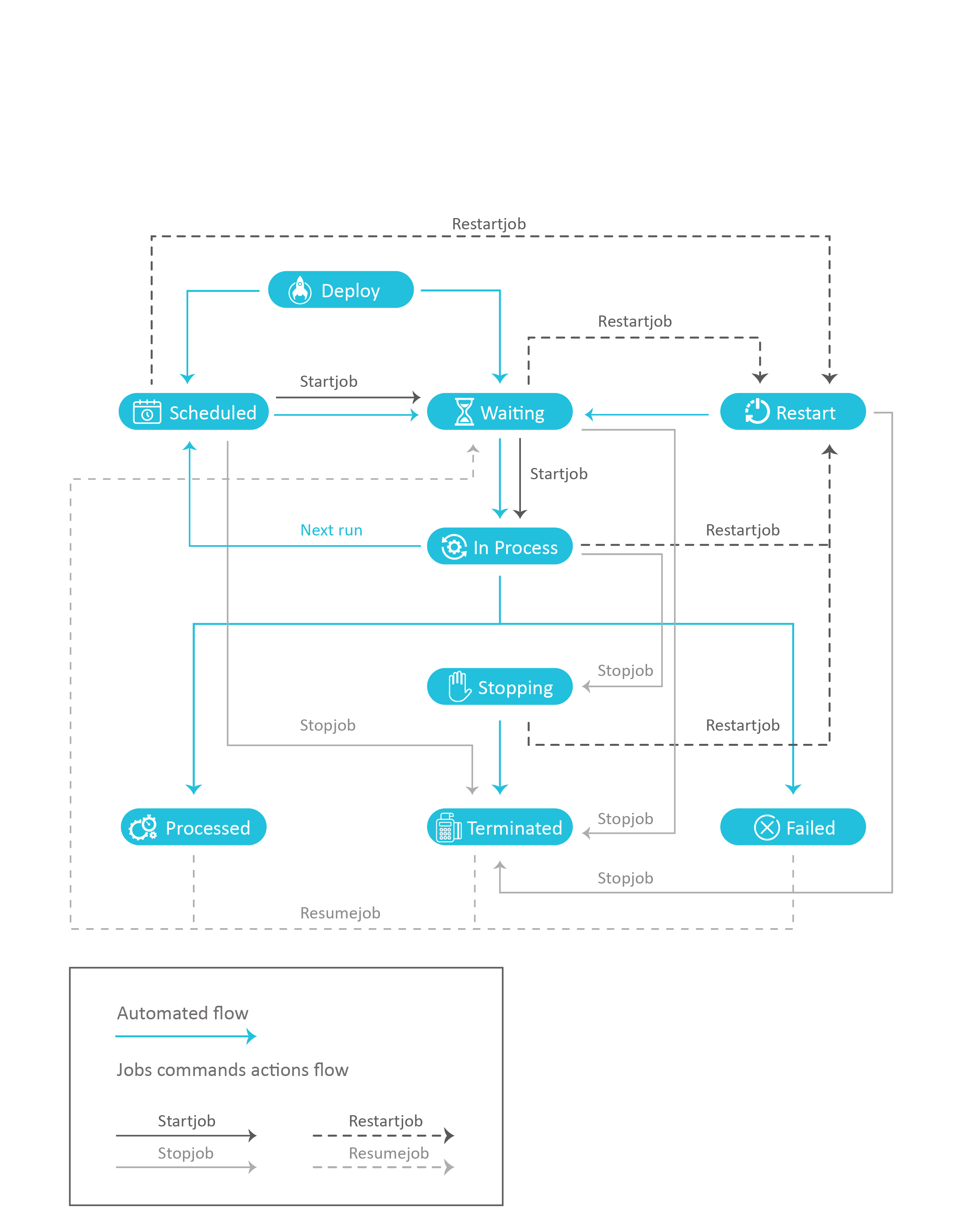
The following image illustrates the different stages of a Job's lifecycle and the different types of actions that transit a specific Job from one specific state to another.
- The blue arrows show the natural path of a Job during its lifecycle in Automatic Execution mode.
- The dotted or plain arrows show the transition between stages in Manual Execution mode when manually applying one of the following commands:
- startjob - plain line
- stopjob - plain line
- restartjob - dotted line
- resumejob - dotted line
Fabric Nodes and Jobs Processes
Nodes Affinity
A specific Job can be assigned to a specific Fabric node by specifying the node's parameters in the Jobs affinity definition table in the Fabric Studio or from the startjob command in the Fabric Runtime environment. Once deployed, the Job is only allocated to the nodes specified in the affinity flag.
Nodes Competition
Node Allocation to a Job
When running multiple Fabric nodes, Jobs can be allocated to different nodes. Once a new Job is automatically or manually started, each node within the Fabric Cluster will compete to execute it. The Fabric internal mechanism ensures an agreement is reached between all nodes and that each Job is executed only once by the best candidate node at any given time. Each Fabric node checks in the k2_jobs table whether a new Job has been deployed and whether it has already been allocated to a node by the internal transactions process or assigned to a specific node by way of affinity.
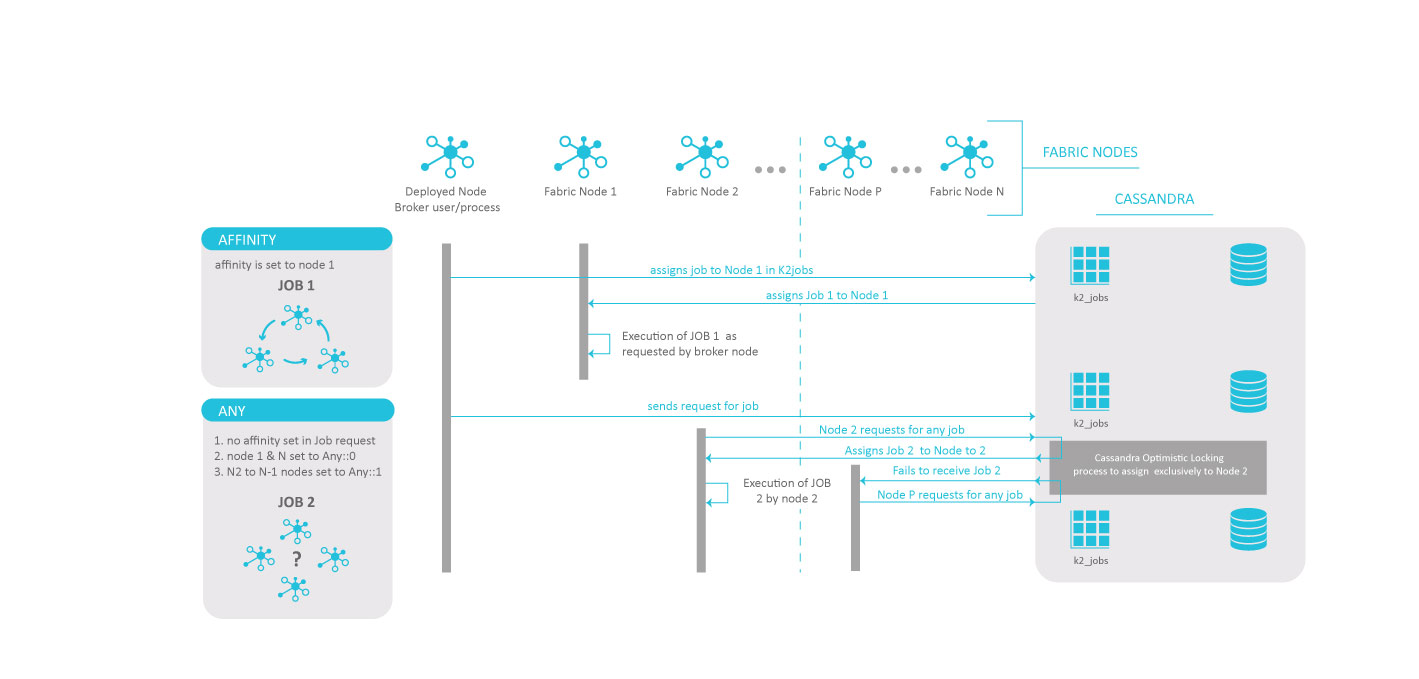
The following image illustrates two different examples:
JOB 1 is allocated to Node 1 because the job's affinity was specifically set to Node 1 in the Fabric Studio from the Job's Parameters Configuration table, or from the Command Line using one of the following commands: startjob and updatejob.
JOB 2 (to which no affinity is set) is allocated to Node 2, as the ANY option has been added to all nodes node.id files from Node 2 to Node (N-1) included. When ANY is set to 0 on the node.id, the node is not part of any job execution. When ANY is set to a value greater than zero, the number shows the maximum number of threads to be allocated to this job.
Jobs Optimistic Locking Configuration
A configurable parameter OPTIMISTIC_LOCKING in the node's config.ini file can be set to support lightweight transactions between nodes to decide on a Job's allocation.
The supported values are as follow:
- NONE - this is the default value. The latest transaction overrides the instance ID.
- QUORUM - the first transaction locks the instance ID. Latest transaction will fail until the transaction is committed (the commit requires a quorum).
- LOCAL QUORUM - the first transaction locks the instance ID. Latest transaction will fail until the transaction is committed (the commit requires a local quorum on the DC).
Job's Logic
Each instance of Fabric runtime server (Fabric node) comprises the dedicated Java logic and classes responsible to handle any Job's lifecycle. Among these classes, the following are particularily significant in the process:
- JobsExecutor - managing the Job's execution and transitions between the different stages, including a multiple retry mechanism when necessary.
- JobsScheduler - managing the node ownership of a specific Job waiting in the queue.
- JobsReconcile - handling the re-allocation of Jobs to a new Fabric node, if the one dedicated through affinity or allocated by the System DB, is not reachable.
Job Execution Resiliency
Fabric ensures that Job executions have multiple recovery opportunities if the node responsible for its execution fails. A heartbeat variable can be configured for each node so that the status of each Fabric node can be monitored and their dedicated Jobs reallocated to different nodes if necessary. If a node restarts, and insufficient time is left before a scheduled Job's execution, the rebooting node has precedence over all other nodes for the execution of this particular Job.


Fabric Jobs Flow
Similar to most Fabric entities, a Job's flow undergoes the following stages:
Fabric Jobs Status
All Fabric Jobs undergo different stages, where each stage indicates a specific step in the Job's handling process:
Statuses
Job's Lifecycle
The following image illustrates the different stages of a Job's lifecycle and the different types of actions that transit a specific Job from one specific state to another.
- The blue arrows show the natural path of a Job during its lifecycle in Automatic Execution mode.
- The dotted or plain arrows show the transition between stages in Manual Execution mode when manually applying one of the following commands:
- startjob - plain line
- stopjob - plain line
- restartjob - dotted line
- resumejob - dotted line
Fabric Nodes and Jobs Processes
Nodes Affinity
A specific Job can be assigned to a specific Fabric node by specifying the node's parameters in the Jobs affinity definition table in the Fabric Studio or from the startjob command in the Fabric Runtime environment. Once deployed, the Job is only allocated to the nodes specified in the affinity flag.
Nodes Competition
Node Allocation to a Job
When running multiple Fabric nodes, Jobs can be allocated to different nodes. Once a new Job is automatically or manually started, each node within the Fabric Cluster will compete to execute it. The Fabric internal mechanism ensures an agreement is reached between all nodes and that each Job is executed only once by the best candidate node at any given time. Each Fabric node checks in the k2_jobs table whether a new Job has been deployed and whether it has already been allocated to a node by the internal transactions process or assigned to a specific node by way of affinity.
The following image illustrates two different examples:
JOB 1 is allocated to Node 1 because the job's affinity was specifically set to Node 1 in the Fabric Studio from the Job's Parameters Configuration table, or from the Command Line using one of the following commands: startjob and updatejob.
JOB 2 (to which no affinity is set) is allocated to Node 2, as the ANY option has been added to all nodes node.id files from Node 2 to Node (N-1) included. When ANY is set to 0 on the node.id, the node is not part of any job execution. When ANY is set to a value greater than zero, the number shows the maximum number of threads to be allocated to this job.
Jobs Optimistic Locking Configuration
A configurable parameter OPTIMISTIC_LOCKING in the node's config.ini file can be set to support lightweight transactions between nodes to decide on a Job's allocation.
The supported values are as follow:
- NONE - this is the default value. The latest transaction overrides the instance ID.
- QUORUM - the first transaction locks the instance ID. Latest transaction will fail until the transaction is committed (the commit requires a quorum).
- LOCAL QUORUM - the first transaction locks the instance ID. Latest transaction will fail until the transaction is committed (the commit requires a local quorum on the DC).
Job's Logic
Each instance of Fabric runtime server (Fabric node) comprises the dedicated Java logic and classes responsible to handle any Job's lifecycle. Among these classes, the following are particularily significant in the process:
- JobsExecutor - managing the Job's execution and transitions between the different stages, including a multiple retry mechanism when necessary.
- JobsScheduler - managing the node ownership of a specific Job waiting in the queue.
- JobsReconcile - handling the re-allocation of Jobs to a new Fabric node, if the one dedicated through affinity or allocated by the System DB, is not reachable.
Job Execution Resiliency
Fabric ensures that Job executions have multiple recovery opportunities if the node responsible for its execution fails. A heartbeat variable can be configured for each node so that the status of each Fabric node can be monitored and their dedicated Jobs reallocated to different nodes if necessary. If a node restarts, and insufficient time is left before a scheduled Job's execution, the rebooting node has precedence over all other nodes for the execution of this particular Job.
