


Rule-driven Synthetic Data Generation
TDM data generation creates synthetic entities based on either rules or AI. The synthetic data is populated into the LU tables, where an LU table can be populated with either source data or generated synthetic data. This article describes the implementation of rule-based data generation.
Implementation of Logical Unit Population
To support synthetic data generation, LU population must be based on Broadway flows rather than DB queries or root functions. Hence, the sourceDbQuery Actor was enhanced (in Fabric 7.1) to support either of the following two population modes: a DB Select query from a data source or a synthetic population. The population mode is set based on the ROWS_GENERATOR key, which is a session variable. When set to true, the sourceDbQuery Actor runs the data generation inner flow to generate synthetic records. The number of synthetic records created for each parent key is determined by the rowsGeneratorDistribution input argument of the sourceDbQuery Actor.
LU Population Flows — Implementation Steps
Verify that the populations of LU tables are based on Broadway flows in order to support synthetic data generation. Note that you need to use the populationRootTable.pop.flow for the main source LU table. For other LU tables, generate the default population flow.
Optional: Edit the default number of generated synthetic records. In the data generation process, it is necessary to define how many records should be generated for each LU table. For example, you must specify the number of addresses to be generated for a synthetic customer.
The rowsGeneratorDistribution input argument of the sourceDbQuery Actor (named Query) in each LU table population flow sets the number of generated records for each table. By default, it generates one record for the main LU table, and between 1 and 3 records are generated for the remaining LU tables. The values '1' and '3' are set in TABLE_DEFAULT_DISTRIBUTION_MIN and TABLE_DEFAULT_DISTRIBUTION_MAX TDM general parameters.
Edit options:
The following methods can be used to override the number range of generated records in a TDM implementation:
i. Edit the default number range of generated records (default is 1 to 3): Update the TABLE_DEFAULT_DISTRIBUTION_MIN and TABLE_DEFAULT_DISTRIBUTION_MAX parameters in the TDM DB. This edit will impact the number of generated records for all LU tables, except for the main source LU table.
Example: Run the following Update statements in order to set the number of generated records to be between 2 and 4:
UPDATE tdm_general_parameters set param_value = '2' where param_name = 'TABLE_DEFAULT_DISTRIBUTION_MIN'; UPDATE tdm_general_parameters set param_value = '4' where param_name = 'TABLE_DEFAULT_DISTRIBUTION_MAX';ii. Edit the rowsGeneratorDistribution input argument in the LU population flow in order to set either a different number range (minimum and maximum values) or a distribution type (default is Uniform distribution) of generated records for a given LU table, if needed. For example, generate customers with 3 to 6 contracts. The data generation randomly generates a number of records within this range:
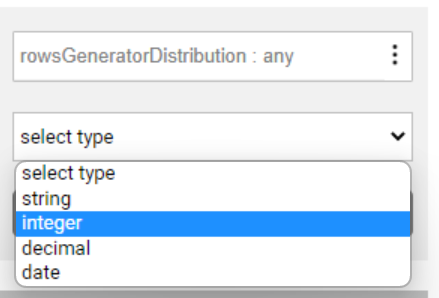
Set the type of the distributed value to integer:
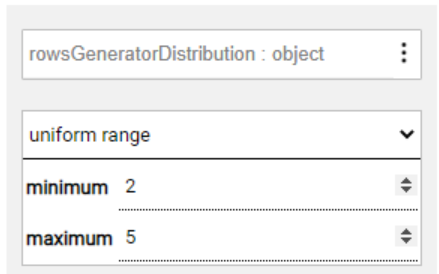
Then, edit the distribution type and/or the minimum and maximum values, as seen in the below example:
Click here for more information about distribution types.
- If you edit the rowsGeneratorDistribution input argument, you must set it as an External parameter using the following naming convention:
[lu name]_[lu table name]_number_of_records
Notes:
If the rowsGeneratorDistribution input argument is edited, but not set as an External parameter, the parameter cannot be overridden by the TDM task.
If the rowsGeneratorDistribution input argument is not edited, it is automatically generated behind the scenes as an external parameter with the following naming convention:
[lu name]_[lu table name]_number_of_recordsFor example: crm_address_number_of_records.
The external parameter enables users to override the number range of generated records for each table in the TDM task. For example, customers should be generated with 2 to 4 addresses and 3 to 6 contracts each.
- Optional: Exclude the number of records for selected tables from the external parameters that can be set in the task. For example, always generate one address for each customer. Do not enable the tester to set the number of generated addresses for each customer in the task. Populate the excluded LU name and LU table in the IgnoreGenerateTableDistList MTable to disable the number of records for selected tables by the task creator.
Implementation of Data Generation Flows
The sourceDbQuery Actor (automatically added to the LU population flow and named Query) runs an inner data generation flow to generate synthetic records for data generation tasks. Data generation flows must be created on each source LU table to support synthetic data generation.
The naming convention for a data generation flow is as follows:
${population name}.generator
For example: activity.pop.generator
Note that a synthetic data generation task execution sets the ROWS_GENERATOR key (session variable) to true, which triggers the execution of the data generation inner flow on each LU table.
Fabric Catalog Integration
From TDM V8.1 onwards, data generation flows are integrated with the Fabric Catalog to generate synthetic data based on field types and source values. Additionally, TDM supports synthetic data generation without using the Fabric Catalog, in cases where the Catalog is not implemented in the TDM project.
The generation flow invokes the CatalogGeneratorRecord Actor to generate synthetic records. The catalog generates the synthetic records based on the following logic:
Option set analyzer - Fabric 8.3.1 added this plugin in order to identify non-sensitive (non-PII) fields with a limited number of distinct values (in the data sample) and save those values in a dedicated MTable, enabling their use in synthetic data generation. The catalog sets one of the field's identified values in the synthetic record. For example, the valid values, identified for the case_status field are 'Unresolved', 'Closed', and 'New'. The catalog generator will get one of these values when generating a synthetic Case record instead of generating a random string for this field.
Default classifications - Fabric 8.3.1 has added a generation of synthetic values based on default classifications in the catalog. Each field type has its own default classification. For example, DEFAULT_STRING, DEFAULT_INTERGER, DEFAULT_DATE etc..
Each default classification has its own data generator and advanced settings. This way, the catalog can generate a synthetic value for a field based on its type and size. The minimum and maximum values for the generated value can be hard-coded in the classification. Alternatively, you can map the minimum and maximum sizes to the field's size in the advanced settings.
- Example:
- The DEFAULT_STRING classification generates a random string using the RandocString Actor.
Data Generation Flows — Implementation Steps
1. Sequence Handling
Map the relevant Sequence names to the related fields in the tables before generating data generation flows. This is required in order to include sequence generation within data generation flows. The TDM templates can get the sequence mapping from either the TDMSeqSrc2TrgMapping Actor or the Catalog.
Click here for Sequence implementation guidelines.
The generated flow sets the sequenceId input argument, which is created in the TDM DB for the generated ID using the following naming convention:
Gen_[the sequence name in TDMSeqSrc2TrgMapping or the Catalog's Sequence name]
Example:
The customer, contract and address tables of the CRM LU have the following sequence mapping:

The data generation flows of these tables create the gen_customer_id_seq, gen_address_id_seq, and gen_contract_id_seq DB sequences in the TDM DB and populate the customer_id, address_id, and contract_id fields using the generated sequences.
2. Create Data Generation Flows for LU Tables
Run the TDMLUInitBasedOnFabric flow and set the CREATE_GENERATE_FLOWS input parameter to true in order to create data generation flows.
The following flows are created for each LU table:
Data generation flow. The naming convention for this flow is:
${population name}.generator.For example: contract.pop.generator
From TDM V8.1 onwards, TDM templates also create inner flows that set default values for table fields based on their types. Such inner flows are called when the Fabric Catalog is not implemented in the TDM project. The naming convention for the inner flow is:
${table name}.typeDefaultsGenerator.For example: contract.typeDefaultsGenerator
Data Generation Flow Logic
Data generation flows are created with the following logic:
IDs:
The data generation flow sends the parent IDs to the child's population flow, based on the parent-child LU schema definition. For example, the Address LU table is the child of the Customer LU table. It is linked to the Customer LU table via the customer_id field. A new customer_id sequence is generated for the Customer LU table. The Address' data generation flow gets the parent_row as the input, and it maps the parent customer_id to the Address record.
IDs that are not linked to a parent LU table are populated by the Sequence Actors based on the fields mapped in the TDMSeqSrc2TrgMapping Actor.
Other fields are populated with synthetic data:
By default, this process calls the CatalogGeneratorRecord Actor to generate the field values based on the Fabric Catalog. If a field's classification is defined in the Catalog, its value is generated based on the classification's data generator. Otherwise, a default value is generated based on the field type.
If no data is returned by the CatalogGeneratorRecord Actor (when the Fabric Catalog is not implemented), then the flow calls the
${table name}.typeDefaultsGeneratorinner flow to utilize data generation Actors according to the fields' data type. Note that these default data generation Actors are selected according to the mappings defined in the GenerateDataDefaultFieldTypeActors constTable (imported from the TDM library under the Shared Objects). This table can be edited to change the default data generators and should be updated before the data generation flows are created.
The output of the data generation flow contains a Map that includes a list of fields. These fields are sent to the related LU population flow and loaded into the LU table as a row column. Note that the data generation flow is called by a loop and returns a single record on each call. By default, the rowsGenerator Actor handles both the loop over the parent rows and the loop over the child IDs for each parent ID.
3. Edit Data Generation Flows
The following manual updates may be required for the data generation flows:
Data Generators
Replacement of the default data generation Actors with other data generators or custom inner flows — this process needs to be done in later flow stages, after the Prepare Generated Data stage (after calling either the CatalogGeneratorRecord Actor or the
${table name}.typeDefaultsGeneratorinner flow).Overridden fields must be added to a Map. Once added, this Map should be sent as the last parameter to the Merge Maps of all Fields Actor within the data generation flow.
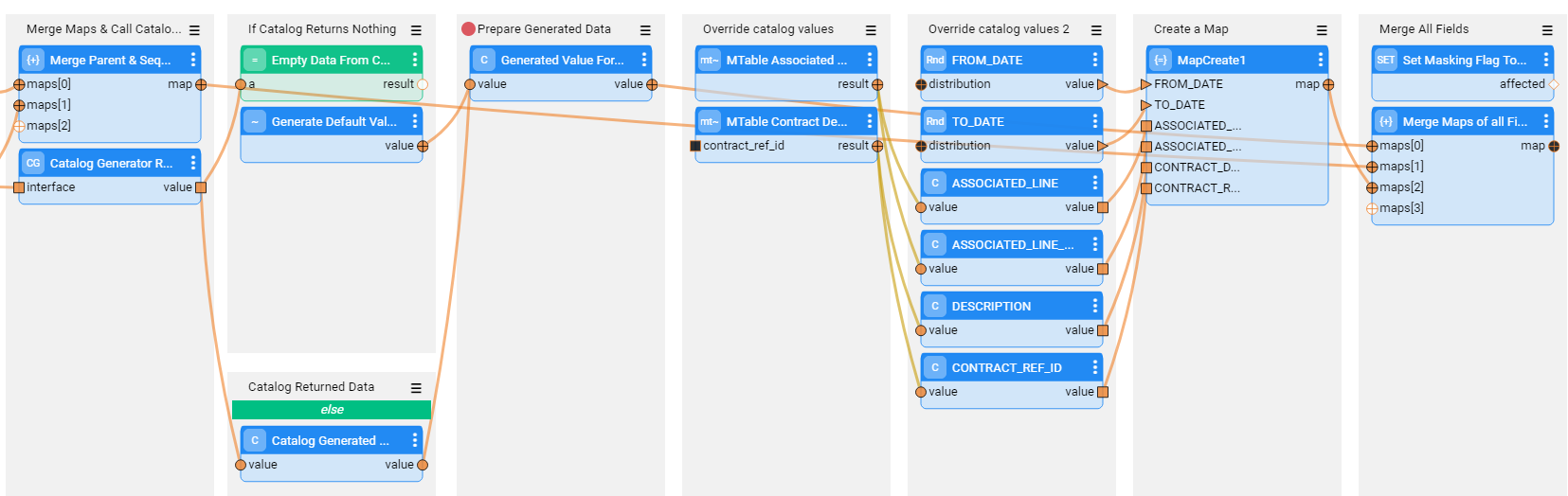
In the below example flow, the logic to generate the Associated_line, Associated_line_fmt, Contract_ref_id, and Description fields is overridden using MTables instead of the default generated values. These fields are added to a Map, and the Map is then sent to the Merge Maps of all Fields Actor:
PII Fields
In general, it is recommended to populate PII fields in the data generation flow and to avoid overriding them with Masking Actors in the LU population flow. This ensures that PII fields can be exposed as external business parameters for data generation tasks, while preserving user-defined values.
The Masking Sensitive Data checkbox should be cleared for the Synthetic environment in the TDM Portal. This prevents PII fields from being masked in LU population flows for data generation tasks.
TDM V8.1 has added a new Actor — GenerateConsistent. This Actor inherits from the Masking Actor but has its own category value — generate_consistent. Using the GenerateConsistent Actor in data generation flows ensures referential integrity across LUs for generated fields.
Notes:
The TDM execution process sets the generate_consistent key to true on data generation tasks.
The new Actor does not require having an input value since there is no original value for newly generated synthetic entities.
If a PII field exists across multiple LUs and is set in several records within the LUI, you should use the Masking Actor instead of the GenerateConsistent Actor. For example, a customer may have multiple contracts, each requiring a different name. The contracts exist in both the CRM and Billing LUs. To handle this, populate the Masking Actor's input parameters in the data generation flow as follows:
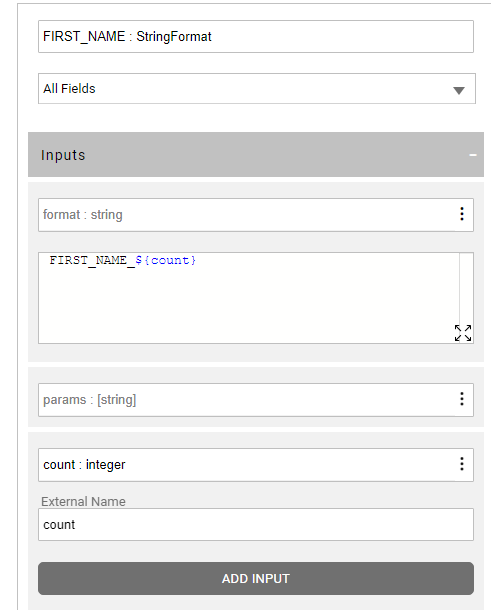
- value — populate it with an initial value of the field name + the record number, e.g., first_name_1, first_name_2, etc. The record number is sent to the data generation flow by the RowsGenerator Actor in the count parameter.
View the example below:
- category — populate it with generate_consistent value.
PII fields can differ in their occurrence across records and in the requirement for referential integrity (consistency). Each scenario requires a different implementation approach.
Example: Both the CRM and Billing LUs — representing separate systems — contain the First Name and Last Name fields. It is required to keep the same combination of the First and Last Names in both LUs for a given customer.
The following table describes the implementation recommendations for each scenario:
Click here for more information about Masking Actors.
External Business Parameters
If users wish to override the default values of parameters that are set in the TDM implementation, they should be able to set their own values. Such overriding is facilitated only if external business parameters, such as City and State, are to be added to data generation flows. The editor of the parameter depends on the parameter type. Spaces and special characters — except for an underscore — are not permitted in the External Name setting.
Click here for more information about integrating the TDM portal with the Broadway editors, as well as implementation guides for MTable and Distribution parameters.
Handling Loops Over the Number of Records
There are several optional modes for executing the data generation inner flow:
- Row by row — this recommended approach is implemented by the data generation flows. The inner flow returns a single row and lets the RowsGenerator Actor handle parent rows and the number of rows per parent ID. The data generation flow can return either multiple results that will serve as the row columns or a single result named result of a Map type.
Note that the data generation flow can be configured to run in different modes, if needed:
- Rows per parent — generation of all records for each input parent ID. For example, generating 2 to 5 open cases and 1 to 6 closed cases per each parent activity ID requires the usage of the 'rows per parent' mode.
- Handle all parent rows — generation of all records for all input parent IDs. The Actor will return these rows and will not call the inner flow again.
Click here for more information and examples related to the RowsGenerator Actor.
Adding a Synthetic Environment
The rule-based data generation task runs in a dummy synthetic environment. This synthetic environment must be added to both Fabric and the TDM self-service application, and its name is defined by the SYNTHETIC_ENVIRONMENT Global. By default, this Global is set to Synthetic, but it can be modified to use a different name.
Notes:
- Fabric — the source and target interfaces can be set as inactive in the synthetic environment. The TDM interface must be active.
- TDM self-service application — the synthetic environment is defined as a source environment in the TDM self-service application, and must have environment_id = -1.


Rule-driven Synthetic Data Generation
TDM data generation creates synthetic entities based on either rules or AI. The synthetic data is populated into the LU tables, where an LU table can be populated with either source data or generated synthetic data. This article describes the implementation of rule-based data generation.
Implementation of Logical Unit Population
To support synthetic data generation, LU population must be based on Broadway flows rather than DB queries or root functions. Hence, the sourceDbQuery Actor was enhanced (in Fabric 7.1) to support either of the following two population modes: a DB Select query from a data source or a synthetic population. The population mode is set based on the ROWS_GENERATOR key, which is a session variable. When set to true, the sourceDbQuery Actor runs the data generation inner flow to generate synthetic records. The number of synthetic records created for each parent key is determined by the rowsGeneratorDistribution input argument of the sourceDbQuery Actor.
LU Population Flows — Implementation Steps
Verify that the populations of LU tables are based on Broadway flows in order to support synthetic data generation. Note that you need to use the populationRootTable.pop.flow for the main source LU table. For other LU tables, generate the default population flow.
Optional: Edit the default number of generated synthetic records. In the data generation process, it is necessary to define how many records should be generated for each LU table. For example, you must specify the number of addresses to be generated for a synthetic customer.
The rowsGeneratorDistribution input argument of the sourceDbQuery Actor (named Query) in each LU table population flow sets the number of generated records for each table. By default, it generates one record for the main LU table, and between 1 and 3 records are generated for the remaining LU tables. The values '1' and '3' are set in TABLE_DEFAULT_DISTRIBUTION_MIN and TABLE_DEFAULT_DISTRIBUTION_MAX TDM general parameters.
Edit options:
The following methods can be used to override the number range of generated records in a TDM implementation:
i. Edit the default number range of generated records (default is 1 to 3): Update the TABLE_DEFAULT_DISTRIBUTION_MIN and TABLE_DEFAULT_DISTRIBUTION_MAX parameters in the TDM DB. This edit will impact the number of generated records for all LU tables, except for the main source LU table.
Example: Run the following Update statements in order to set the number of generated records to be between 2 and 4:
UPDATE tdm_general_parameters set param_value = '2' where param_name = 'TABLE_DEFAULT_DISTRIBUTION_MIN'; UPDATE tdm_general_parameters set param_value = '4' where param_name = 'TABLE_DEFAULT_DISTRIBUTION_MAX';ii. Edit the rowsGeneratorDistribution input argument in the LU population flow in order to set either a different number range (minimum and maximum values) or a distribution type (default is Uniform distribution) of generated records for a given LU table, if needed. For example, generate customers with 3 to 6 contracts. The data generation randomly generates a number of records within this range:
Set the type of the distributed value to integer:
Then, edit the distribution type and/or the minimum and maximum values, as seen in the below example:
Click here for more information about distribution types.
- If you edit the rowsGeneratorDistribution input argument, you must set it as an External parameter using the following naming convention:
[lu name]_[lu table name]_number_of_records
Notes:
If the rowsGeneratorDistribution input argument is edited, but not set as an External parameter, the parameter cannot be overridden by the TDM task.
If the rowsGeneratorDistribution input argument is not edited, it is automatically generated behind the scenes as an external parameter with the following naming convention:
[lu name]_[lu table name]_number_of_recordsFor example: crm_address_number_of_records.
The external parameter enables users to override the number range of generated records for each table in the TDM task. For example, customers should be generated with 2 to 4 addresses and 3 to 6 contracts each.
- Optional: Exclude the number of records for selected tables from the external parameters that can be set in the task. For example, always generate one address for each customer. Do not enable the tester to set the number of generated addresses for each customer in the task. Populate the excluded LU name and LU table in the IgnoreGenerateTableDistList MTable to disable the number of records for selected tables by the task creator.
Implementation of Data Generation Flows
The sourceDbQuery Actor (automatically added to the LU population flow and named Query) runs an inner data generation flow to generate synthetic records for data generation tasks. Data generation flows must be created on each source LU table to support synthetic data generation.
The naming convention for a data generation flow is as follows:
${population name}.generator
For example: activity.pop.generator
Note that a synthetic data generation task execution sets the ROWS_GENERATOR key (session variable) to true, which triggers the execution of the data generation inner flow on each LU table.
Fabric Catalog Integration
From TDM V8.1 onwards, data generation flows are integrated with the Fabric Catalog to generate synthetic data based on field types and source values. Additionally, TDM supports synthetic data generation without using the Fabric Catalog, in cases where the Catalog is not implemented in the TDM project.
The generation flow invokes the CatalogGeneratorRecord Actor to generate synthetic records. The catalog generates the synthetic records based on the following logic:
Option set analyzer - Fabric 8.3.1 added this plugin in order to identify non-sensitive (non-PII) fields with a limited number of distinct values (in the data sample) and save those values in a dedicated MTable, enabling their use in synthetic data generation. The catalog sets one of the field's identified values in the synthetic record. For example, the valid values, identified for the case_status field are 'Unresolved', 'Closed', and 'New'. The catalog generator will get one of these values when generating a synthetic Case record instead of generating a random string for this field.
Default classifications - Fabric 8.3.1 has added a generation of synthetic values based on default classifications in the catalog. Each field type has its own default classification. For example, DEFAULT_STRING, DEFAULT_INTERGER, DEFAULT_DATE etc..
Each default classification has its own data generator and advanced settings. This way, the catalog can generate a synthetic value for a field based on its type and size. The minimum and maximum values for the generated value can be hard-coded in the classification. Alternatively, you can map the minimum and maximum sizes to the field's size in the advanced settings.
- Example:
- The DEFAULT_STRING classification generates a random string using the RandocString Actor.
Data Generation Flows — Implementation Steps
1. Sequence Handling
Map the relevant Sequence names to the related fields in the tables before generating data generation flows. This is required in order to include sequence generation within data generation flows. The TDM templates can get the sequence mapping from either the TDMSeqSrc2TrgMapping Actor or the Catalog.
Click here for Sequence implementation guidelines.
The generated flow sets the sequenceId input argument, which is created in the TDM DB for the generated ID using the following naming convention:
Gen_[the sequence name in TDMSeqSrc2TrgMapping or the Catalog's Sequence name]
Example:
The customer, contract and address tables of the CRM LU have the following sequence mapping:
The data generation flows of these tables create the gen_customer_id_seq, gen_address_id_seq, and gen_contract_id_seq DB sequences in the TDM DB and populate the customer_id, address_id, and contract_id fields using the generated sequences.
2. Create Data Generation Flows for LU Tables
Run the TDMLUInitBasedOnFabric flow and set the CREATE_GENERATE_FLOWS input parameter to true in order to create data generation flows.
The following flows are created for each LU table:
Data generation flow. The naming convention for this flow is:
${population name}.generator.For example: contract.pop.generator
From TDM V8.1 onwards, TDM templates also create inner flows that set default values for table fields based on their types. Such inner flows are called when the Fabric Catalog is not implemented in the TDM project. The naming convention for the inner flow is:
${table name}.typeDefaultsGenerator.For example: contract.typeDefaultsGenerator
Data Generation Flow Logic
Data generation flows are created with the following logic:
IDs:
The data generation flow sends the parent IDs to the child's population flow, based on the parent-child LU schema definition. For example, the Address LU table is the child of the Customer LU table. It is linked to the Customer LU table via the customer_id field. A new customer_id sequence is generated for the Customer LU table. The Address' data generation flow gets the parent_row as the input, and it maps the parent customer_id to the Address record.
IDs that are not linked to a parent LU table are populated by the Sequence Actors based on the fields mapped in the TDMSeqSrc2TrgMapping Actor.
Other fields are populated with synthetic data:
By default, this process calls the CatalogGeneratorRecord Actor to generate the field values based on the Fabric Catalog. If a field's classification is defined in the Catalog, its value is generated based on the classification's data generator. Otherwise, a default value is generated based on the field type.
If no data is returned by the CatalogGeneratorRecord Actor (when the Fabric Catalog is not implemented), then the flow calls the
${table name}.typeDefaultsGeneratorinner flow to utilize data generation Actors according to the fields' data type. Note that these default data generation Actors are selected according to the mappings defined in the GenerateDataDefaultFieldTypeActors constTable (imported from the TDM library under the Shared Objects). This table can be edited to change the default data generators and should be updated before the data generation flows are created.
The output of the data generation flow contains a Map that includes a list of fields. These fields are sent to the related LU population flow and loaded into the LU table as a row column. Note that the data generation flow is called by a loop and returns a single record on each call. By default, the rowsGenerator Actor handles both the loop over the parent rows and the loop over the child IDs for each parent ID.
3. Edit Data Generation Flows
The following manual updates may be required for the data generation flows:
Data Generators
Replacement of the default data generation Actors with other data generators or custom inner flows — this process needs to be done in later flow stages, after the Prepare Generated Data stage (after calling either the CatalogGeneratorRecord Actor or the
${table name}.typeDefaultsGeneratorinner flow).Overridden fields must be added to a Map. Once added, this Map should be sent as the last parameter to the Merge Maps of all Fields Actor within the data generation flow.
In the below example flow, the logic to generate the Associated_line, Associated_line_fmt, Contract_ref_id, and Description fields is overridden using MTables instead of the default generated values. These fields are added to a Map, and the Map is then sent to the Merge Maps of all Fields Actor:
PII Fields
In general, it is recommended to populate PII fields in the data generation flow and to avoid overriding them with Masking Actors in the LU population flow. This ensures that PII fields can be exposed as external business parameters for data generation tasks, while preserving user-defined values.
The Masking Sensitive Data checkbox should be cleared for the Synthetic environment in the TDM Portal. This prevents PII fields from being masked in LU population flows for data generation tasks.
TDM V8.1 has added a new Actor — GenerateConsistent. This Actor inherits from the Masking Actor but has its own category value — generate_consistent. Using the GenerateConsistent Actor in data generation flows ensures referential integrity across LUs for generated fields.
Notes:
The TDM execution process sets the generate_consistent key to true on data generation tasks.
The new Actor does not require having an input value since there is no original value for newly generated synthetic entities.
If a PII field exists across multiple LUs and is set in several records within the LUI, you should use the Masking Actor instead of the GenerateConsistent Actor. For example, a customer may have multiple contracts, each requiring a different name. The contracts exist in both the CRM and Billing LUs. To handle this, populate the Masking Actor's input parameters in the data generation flow as follows:
- value — populate it with an initial value of the field name + the record number, e.g., first_name_1, first_name_2, etc. The record number is sent to the data generation flow by the RowsGenerator Actor in the count parameter.
View the example below:
- category — populate it with generate_consistent value.
PII fields can differ in their occurrence across records and in the requirement for referential integrity (consistency). Each scenario requires a different implementation approach.
Example: Both the CRM and Billing LUs — representing separate systems — contain the First Name and Last Name fields. It is required to keep the same combination of the First and Last Names in both LUs for a given customer.
The following table describes the implementation recommendations for each scenario:
Click here for more information about Masking Actors.
External Business Parameters
If users wish to override the default values of parameters that are set in the TDM implementation, they should be able to set their own values. Such overriding is facilitated only if external business parameters, such as City and State, are to be added to data generation flows. The editor of the parameter depends on the parameter type. Spaces and special characters — except for an underscore — are not permitted in the External Name setting.
Click here for more information about integrating the TDM portal with the Broadway editors, as well as implementation guides for MTable and Distribution parameters.
Handling Loops Over the Number of Records
There are several optional modes for executing the data generation inner flow:
- Row by row — this recommended approach is implemented by the data generation flows. The inner flow returns a single row and lets the RowsGenerator Actor handle parent rows and the number of rows per parent ID. The data generation flow can return either multiple results that will serve as the row columns or a single result named result of a Map type.
Note that the data generation flow can be configured to run in different modes, if needed:
- Rows per parent — generation of all records for each input parent ID. For example, generating 2 to 5 open cases and 1 to 6 closed cases per each parent activity ID requires the usage of the 'rows per parent' mode.
- Handle all parent rows — generation of all records for all input parent IDs. The Actor will return these rows and will not call the inner flow again.
Click here for more information and examples related to the RowsGenerator Actor.
Adding a Synthetic Environment
The rule-based data generation task runs in a dummy synthetic environment. This synthetic environment must be added to both Fabric and the TDM self-service application, and its name is defined by the SYNTHETIC_ENVIRONMENT Global. By default, this Global is set to Synthetic, but it can be modified to use a different name.
Notes:
- Fabric — the source and target interfaces can be set as inactive in the synthetic environment. The TDM interface must be active.
- TDM self-service application — the synthetic environment is defined as a source environment in the TDM self-service application, and must have environment_id = -1.
