


Logical Unit Concepts
Data Product
A Data Product is K2View’s term for a reusable, domain-specific “package” of data that's prepared, governed, and delivered to users or applications. It aligns with the modern data mesh philosophy, where:
Data domain teams treat data assets like software products—managing them end-to-end (define, engineer, test, deploy, monitor).
A Data Product is centered on a specific business entity (like a customer, order, loan).
It bundles everything needed:
- Schema (tables, fields, relationships)
- Integration flows to pull from source systems
- Transformations (cleansing, enrichment, masking)
- Access interfaces (APIs, virtualization)
The goal: One trusted, governed, accessible dataset per business entity—always current and compliant
Logical Unit (LU)
In K2View’s Fabric Studio, a Logical Unit (LU), also referred to as a Logical Unit Type (LUT), is the blueprint or definition of a Data Product. It consists of:
- LU Schema: Defines root table, related tables, and their relationships.
- LU Tables: Structures (columns, keys, indexes) holding the data.
- LU Table Populations: Integration pipelines—specifying how data is sourced, transformed, and loaded.
- Supporting components: functions, parsers, jobs, instance groups, etc..
- Properties: Storage settings, sync policies, events, security, caching.
A Logical Unit is thus the template used to create actual data stores.
Logical Unit Instance (LUI)
When a Logical Unit is executed or deployed, it creates one or more LU Instances (LUIs) — these are the physical representations of the Data Product for specific entity entries (e.g., each customer record).
- If your Customer LU is applied to 35 million customers, the system generates 35M LUIs—one isolated micro-database (e.g., SQLite/Cassandra/S3) per customer.
- Each LUI holds that entity’s integrated data, kept in sync and governed individually.
How They're Connected
- Data Product = the concept/domain. It’s what you want to build—say, “Customer 360”.
- Logical Unit = the design artifact in K2View Fabric that defines that Data Product: schema, pipelines, policies.
- LU Instances = the runtime deliverables—physical micro-databases each holding that product’s data for individual entities.
So the flow is:
- Define a Logical Unit (Data Product blueprint) → Fabric auto-generates LU Instances, each holding one entity’s data → these are managed, accessed, and governed individually, but all under one Data Product.
Logical Unit Details
The LU is the prototype from which LU Instances (LUIs) are created.
An LU is defined and configured in the Fabric Studio as a core element of the Fabric project. These definitions are comprised of 3 main types of objects:
LU Table: The definition of a table within the LU Schema, with its columns, primary keys, indexes, and triggers.
-
- Data feeding into LU tables from a variety of data sources and keeping it up to date.
- Ability to manipulate the fed data, which includes enriching, cleansing, masking, transforming, etc.
LU Schema: The relationship between the LU tables (similar to foreign keys). An LU schema has one LU table defined as its Root Table. The Root Table holds the LU’s unique key.
In addition to these main objects, others are part of the logical unit and are used to define its life cycle. They can be found in the Project Tree, under each logical unit:
Instance Groups
Resources - files that can be saved as part of a project
IIDFinder
Parsers
Jobs
Let’s use an example of a Customer 360 implementation for Company ABC:
- LU / Data Product: Customer.
- Data sources: CRM, Ordering, Billing and Collection,Billing and Assets.
- LU tables: The tables that will hold the data you wish to keep about a customer from the 4 data sources.
- LU Table Populations: The set of definitions that will be used for extracting, transforming, cleaning, aggregating, validating (etc.) the data from the 4 data sources into the LU tables.
- LU schema: The definition of the Root Table and the relationship between all LU tables.
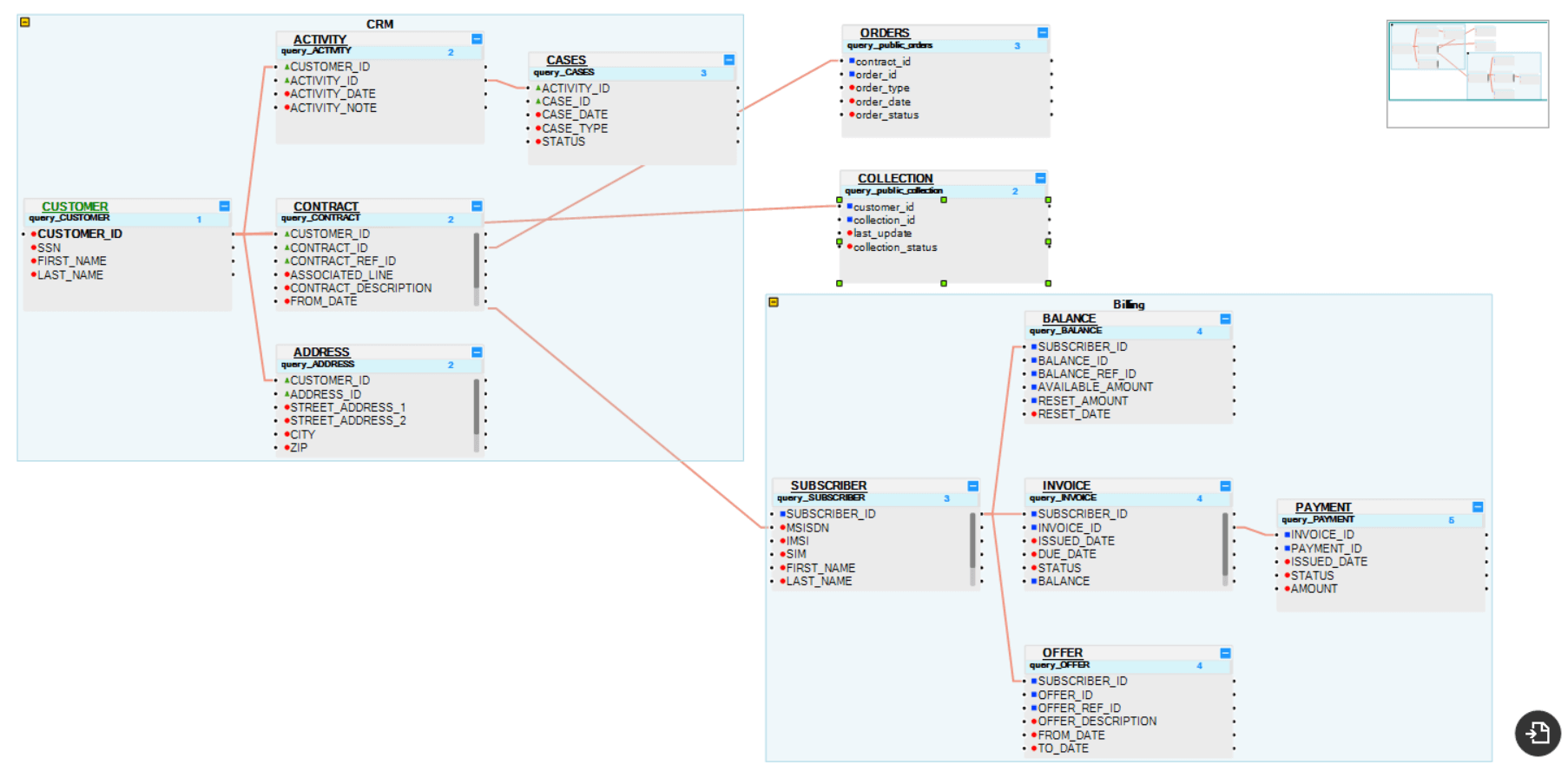

Using our example from above (Customer 360), assume that Company ABC has 35 million customers:
- LU/LUT = Customer
- LUI = one single customer database
Fabric will hold 35 million instances (LUIs) of the Customer LUT. That is, one physical database for each customer.
Things to Consider Before Designing an LU
Every Fabric project starts by defining its LUs. Analyze the business requirements and understand how the consuming application will use the data. Use this information to define the different Business Entities to implement and build an LU for each Business Entity.
General Recommendations for Designing an LU
A business entity is often split between different data sources. In some cases, it is preferable to create one LU that contains all data sources. In other cases, it is more advantageous to split the LUs and create a separate LU for each data source.
Generally, an LU should be based on the smallest number of data sources, as long as it provides a comprehensive view of a Data Product.
For example, if you have a Data Product called Customer, but different Customer Types (e.g., consumer and business) have different data sources, the recommended approach is to create an LU for each subtype (in our example, the different Customer Types).
Below is a pros and cons table of each alternative:
Note:
The file name's ambiguity is not supported within the same Logical Unit. This is not restricted by the Fabric Studio intentionally, allowing the implementor to continue the work and update the names later. For example, if 2 Java function files with identical names were exported from other projects or libraries, they can be saved in the project in the Fabric Studio.
However, at run-time, there should be no ambiguity within the LU, otherwise, the server will run the first file it finds (with no commitment as to what is considered the first one).

Logical Unit Concepts
Data Product
A Data Product is K2View’s term for a reusable, domain-specific “package” of data that's prepared, governed, and delivered to users or applications. It aligns with the modern data mesh philosophy, where:
Data domain teams treat data assets like software products—managing them end-to-end (define, engineer, test, deploy, monitor).
A Data Product is centered on a specific business entity (like a customer, order, loan).
It bundles everything needed:
- Schema (tables, fields, relationships)
- Integration flows to pull from source systems
- Transformations (cleansing, enrichment, masking)
- Access interfaces (APIs, virtualization)
The goal: One trusted, governed, accessible dataset per business entity—always current and compliant
Logical Unit (LU)
In K2View’s Fabric Studio, a Logical Unit (LU), also referred to as a Logical Unit Type (LUT), is the blueprint or definition of a Data Product. It consists of:
- LU Schema: Defines root table, related tables, and their relationships.
- LU Tables: Structures (columns, keys, indexes) holding the data.
- LU Table Populations: Integration pipelines—specifying how data is sourced, transformed, and loaded.
- Supporting components: functions, parsers, jobs, instance groups, etc..
- Properties: Storage settings, sync policies, events, security, caching.
A Logical Unit is thus the template used to create actual data stores.
Logical Unit Instance (LUI)
When a Logical Unit is executed or deployed, it creates one or more LU Instances (LUIs) — these are the physical representations of the Data Product for specific entity entries (e.g., each customer record).
- If your Customer LU is applied to 35 million customers, the system generates 35M LUIs—one isolated micro-database (e.g., SQLite/Cassandra/S3) per customer.
- Each LUI holds that entity’s integrated data, kept in sync and governed individually.
How They're Connected
- Data Product = the concept/domain. It’s what you want to build—say, “Customer 360”.
- Logical Unit = the design artifact in K2View Fabric that defines that Data Product: schema, pipelines, policies.
- LU Instances = the runtime deliverables—physical micro-databases each holding that product’s data for individual entities.
So the flow is:
- Define a Logical Unit (Data Product blueprint) → Fabric auto-generates LU Instances, each holding one entity’s data → these are managed, accessed, and governed individually, but all under one Data Product.
Logical Unit Details
The LU is the prototype from which LU Instances (LUIs) are created.
An LU is defined and configured in the Fabric Studio as a core element of the Fabric project. These definitions are comprised of 3 main types of objects:
LU Table: The definition of a table within the LU Schema, with its columns, primary keys, indexes, and triggers.
-
- Data feeding into LU tables from a variety of data sources and keeping it up to date.
- Ability to manipulate the fed data, which includes enriching, cleansing, masking, transforming, etc.
LU Schema: The relationship between the LU tables (similar to foreign keys). An LU schema has one LU table defined as its Root Table. The Root Table holds the LU’s unique key.
In addition to these main objects, others are part of the logical unit and are used to define its life cycle. They can be found in the Project Tree, under each logical unit:
Instance Groups
Resources - files that can be saved as part of a project
IIDFinder
Parsers
Jobs
Let’s use an example of a Customer 360 implementation for Company ABC:
- LU / Data Product: Customer.
- Data sources: CRM, Ordering, Billing and Collection,Billing and Assets.
- LU tables: The tables that will hold the data you wish to keep about a customer from the 4 data sources.
- LU Table Populations: The set of definitions that will be used for extracting, transforming, cleaning, aggregating, validating (etc.) the data from the 4 data sources into the LU tables.
- LU schema: The definition of the Root Table and the relationship between all LU tables.
Using our example from above (Customer 360), assume that Company ABC has 35 million customers:
- LU/LUT = Customer
- LUI = one single customer database
Fabric will hold 35 million instances (LUIs) of the Customer LUT. That is, one physical database for each customer.
Things to Consider Before Designing an LU
Every Fabric project starts by defining its LUs. Analyze the business requirements and understand how the consuming application will use the data. Use this information to define the different Business Entities to implement and build an LU for each Business Entity.
General Recommendations for Designing an LU
A business entity is often split between different data sources. In some cases, it is preferable to create one LU that contains all data sources. In other cases, it is more advantageous to split the LUs and create a separate LU for each data source.
Generally, an LU should be based on the smallest number of data sources, as long as it provides a comprehensive view of a Data Product.
For example, if you have a Data Product called Customer, but different Customer Types (e.g., consumer and business) have different data sources, the recommended approach is to create an LU for each subtype (in our example, the different Customer Types).
Below is a pros and cons table of each alternative:
Note:
The file name's ambiguity is not supported within the same Logical Unit. This is not restricted by the Fabric Studio intentionally, allowing the implementor to continue the work and update the names later. For example, if 2 Java function files with identical names were exported from other projects or libraries, they can be saved in the project in the Fabric Studio.
However, at run-time, there should be no ambiguity within the LU, otherwise, the server will run the first file it finds (with no commitment as to what is considered the first one).
