

Fabric Data Masking
Data Privacy laws require the ability to mask data by hiding the original values with a modified content. Fabric provides a field-level API to protect data that is classified as Personal Identifiable Information, sensitive personal data, or commercially sensitive data.
To ensure that the data is still valid for your data lifecycle management, the masked data will look real and appear consistent.
This capability can be used for conducting tests, implementing data transformations, or providing anonymized data to external 3rd parties via web services or queue messages.
Masking Flow
The masking of sensitive data can be done by either the LU Table Population Broadway Flow that runs during the LUI sync before saving the LUI in Fabric, or by using a Broadway flow to mask the LUI data before it is loaded to the target.
The masking process consists of 2 main parts:
Data generation - generating a random masked value for the masked field.
Data consistency - verifying that the same original value gets the same masked value.
Fabric supports 2 methods to keep the data consistency:
- Data consistency using table.
- Data consistency using seed.
The data consistency method is set based on the interface parameter of the Masking Actor: If the interface parameter is populated with SEED, the masking mechanism keeps the Data consistency using seed method.
Data Consistency Using Table
The mapping between the hashed original and masked values is kept in a caching table, which is defined under the k2masking schema.
The following diagram describes the sensitive data masking process, using an LUI sync:
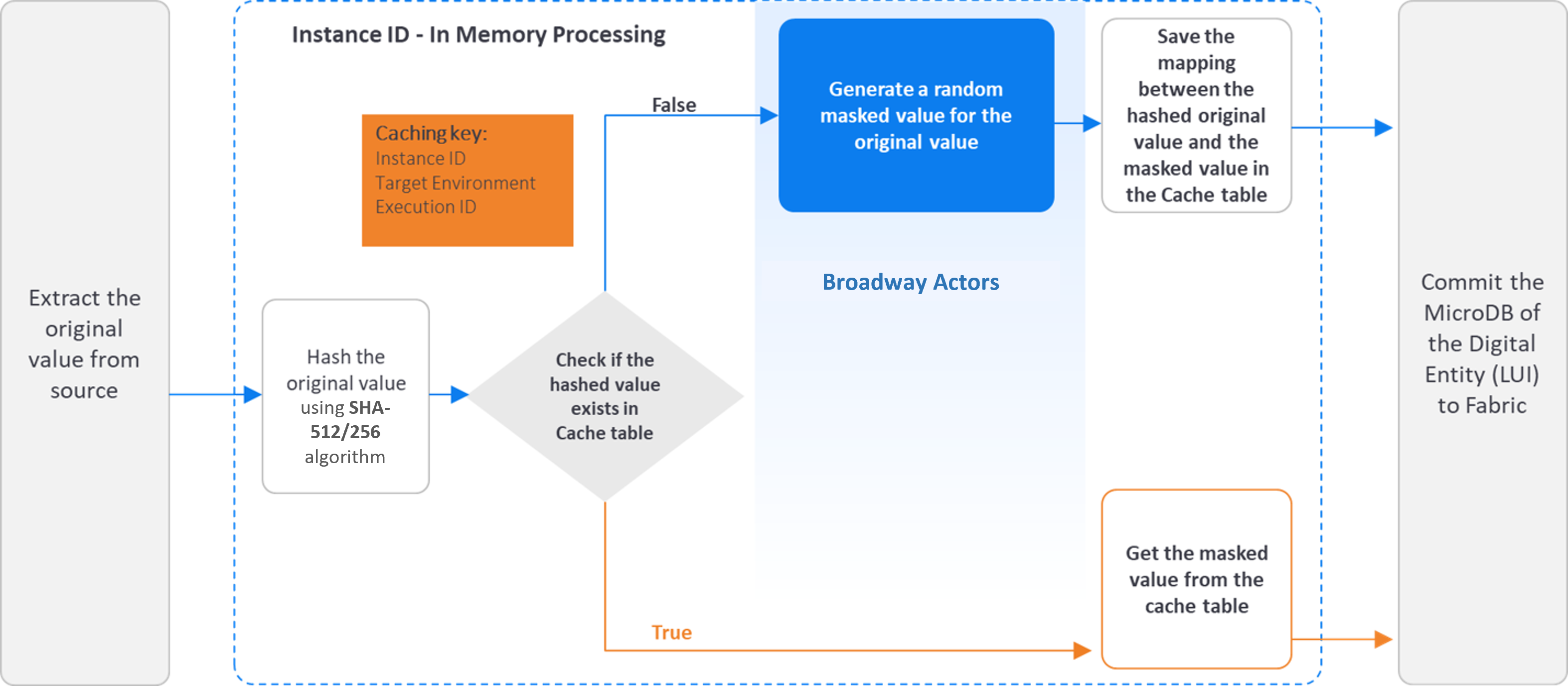
The following diagram describes the sensitive data masking process before loading the data to the target:
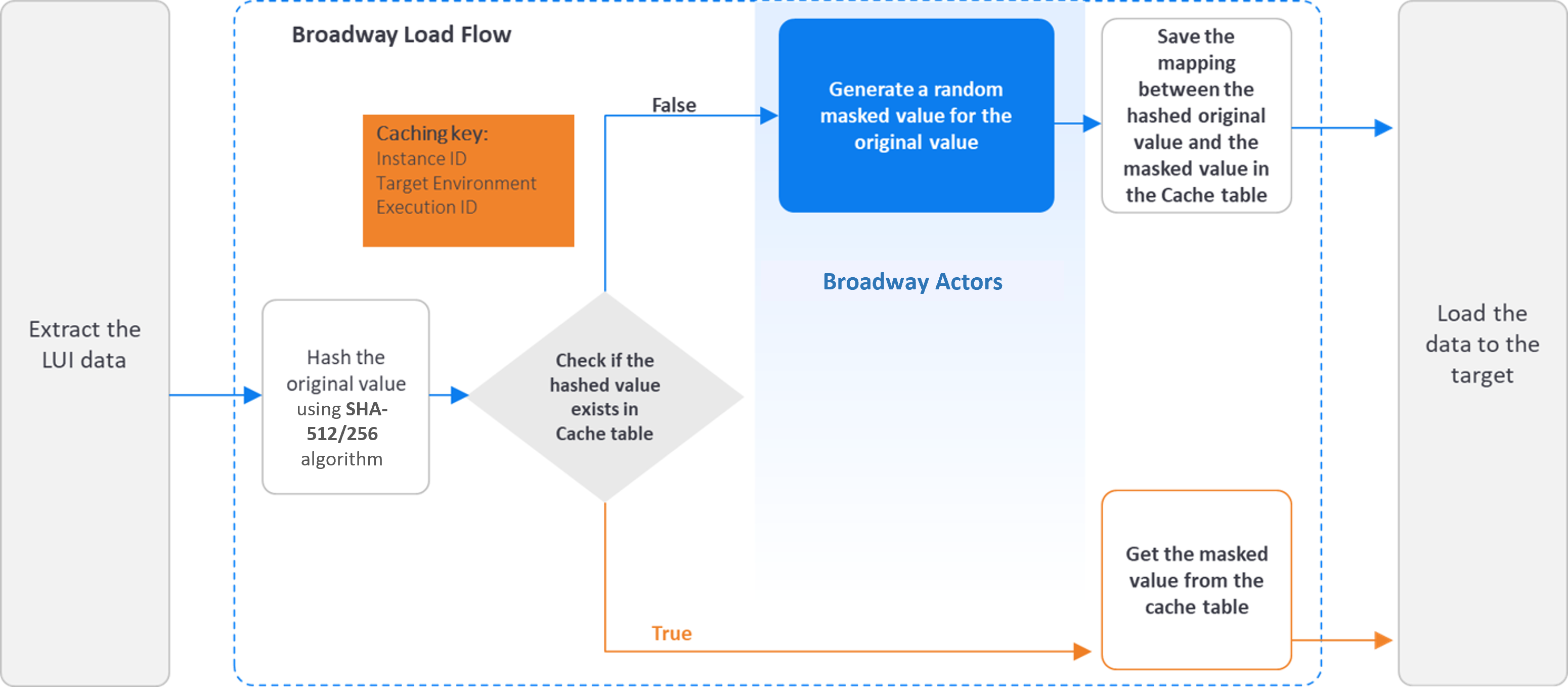
Data Consistency Using Seed
This new method has been added in Fabric 8.2. and it ensures referential integrity without saving the mapping between the hashed original value and the masked value in the caching table. It can therefore lead to better performance, when compared to regular masking, as it does not need to access the DB. The mapping between the hashed original value and the masked value is not kept in the caching table, but rather in the Java Random method using a seed. A seed is like a starting point for generating random numbers, and it ensures consistency of the generated value.
If the Masking actor's interface input argument is populated with SEED, the masking Actor populates the seed with the caching key and sends it to the data generation Actor.
This is available only if the data generation Actor has a seed input argument, and it uses the Java Random method to get the masked value when the input seed is populated. All the built-in data generation Actors support data generation based on seed.
Notes:
In both data consistency methods, Fabric uses the SHA-512 or SHA-512/256 algorithms to hash the original value. Additionally, Fabric uses a dedicated master key to salt the original value before hashing it. The hashing is a one-way activity. The hashed value cannot be reversed back to the original value.
Click here for more information about the Fabric hashing mechanism.
The Data Consistency Using Seed does not keep the referential integrity when the masked value is taken from a dynamic list: If the seed is identical, the random function will bring the same index from the list. It checks the index of the returned value and not the value itself. We therefore recommend to use the Data Consistency Using Table method for keeping the referential integrity in this case.
For example, an MTable that contains a list of names is created at run-time. The 5th index is populated with 'Jonn' on the first run and 'Harry' on the second. If the first run gets 'John', the second run will get 'Harry' when running on the same seed as the first run. This happens because both names have the same index in this example.
The masked value is impacted not only by the seed, but also by the data generation parameters. For example, getting a random value between 0-100 returns a different result than when getting a random value between 0-200, even if they get the same seed value.
The Consistent and unique consistency mode does not support data consistency using seed. Instead, it relies on tables within the k2masking schema to ensure both data consistency and uniqueness of masked values.
Broadway Masking Actors
The masking process is executed by Broadway Actors that enable masking sensitive data before it is loaded into a target database or even into Fabric. The masking process contains the generation (manufacturing) of a random synthetic value that replaces the real value, and the caching of the hashed original value and the masked value in order to keep the referential integrity of the data. Starting from V7.1, Fabric separates data generation (manufacturing) from the hashing and caching capabilities. Broadway provides the following Actors:
- Various data generation Actors under the generators category to generate a random synthetic value. For example: RandomString, RandomNumber, Sequence…
- Masking Actor - this Actor can wrap any data generation Actor and add the hashing and caching capabilities on top of the data generation Actor.
- Broadway still keeps the existing masking Actors for backward compatibility reasons.
The masking Actors use the Fabric hashing utility to hash the original value, and to save the mapping of the hashed and the masked values to the cache table.
Click here to read how to use Fabric's masking Broadway Actors.
Click here to read more about the Fabric hashing mechanism.
Customized Masking Logic
K2view enables users to create their own masking functions:
- The MaskingLuFunction Broadway Actor can be used to call a customized function (a shared function or an LU's function) - to mask the required field.
- The MaskingInnerFlow Broadway Actor can be used to call a customized Broadway flow or an Actor - to mask the required field.
- Fabric 7.1 provides the general Masking Actor that enables running either a customized inner flow or an Actor - to mask a required field.
Click here for more information about the data generators implementation.
The use of MaskingLuFunction, MaskingInnerFlow or Masking Actors guarantees the usage of the masking mechanism, including SHA-512/256 hashing and caching capabilities. The user does not need to handle them by their customized function.
Masking Actors Properties
Interface
- The interface to be used to cache the masked values. If the interface is populated with SEED, the Masking Actor populates the seed with the caching key and sends it to the data generation Actor.
Target Value Uniqueness
- The user can decide whether the masked value is unique per original value (hashed value) or if it can be used for more than one original value. For example, a masked SSN must be unique, but a masked Family Name can be the masked value of different original values.
Cache with Expiration Date
- Each cached link of a hashed value to a masked value can have a TTL (Time To Live). This link will expire once the TTL has been reached, and the original value will be masked again.
Caching Key - Caching Level Parameters
- The caching of the masked values can be saved on different levels, based on the user’s input. Each one of the following parameters can be enabled or disabled from being a part of the Caching key:
- Instance ID
- Environment
- Execution ID
Format Preserving Masking
Format-preserving masking, introduced in Fabric 8.0, provides a solution for maintaining consistent data masking across multiple fields while preserving their original formatting patterns. It addresses scenarios where the same underlying value appears in multiple fields with different formatting patterns.
An optional parameter has been added to the Masking Actor - formatter - to enable format-preserving masking. This parameter can be set with either a formatter flow or an Actor in order to preserve the original format in the masked value and to set the same masked values to all fields that have the same normalized (’naked‘) value, although each field has a different format.
Example:
- The phone number exists in multiple fields in the data source in different formats: +1 (254) 455 5666, +1(254)4555666, +1 (254)-455-5666.
- All these fields must get the same masked value (as they correspond to a single phone number), but the format needs to be different for each field in order to match its original format.
|
Original Value |
Masked Value |
|
+1 (254) 455 5666 |
+1 (254) 430 8992 |
|
+1(254)4555666 |
+1(254)4308992 |
|
+1 (254)-455-5666 |
+1 (254)-430-8992 |
The following diagram describes how the Masking Actor uses the formatter for preserving the original format in the masked value:
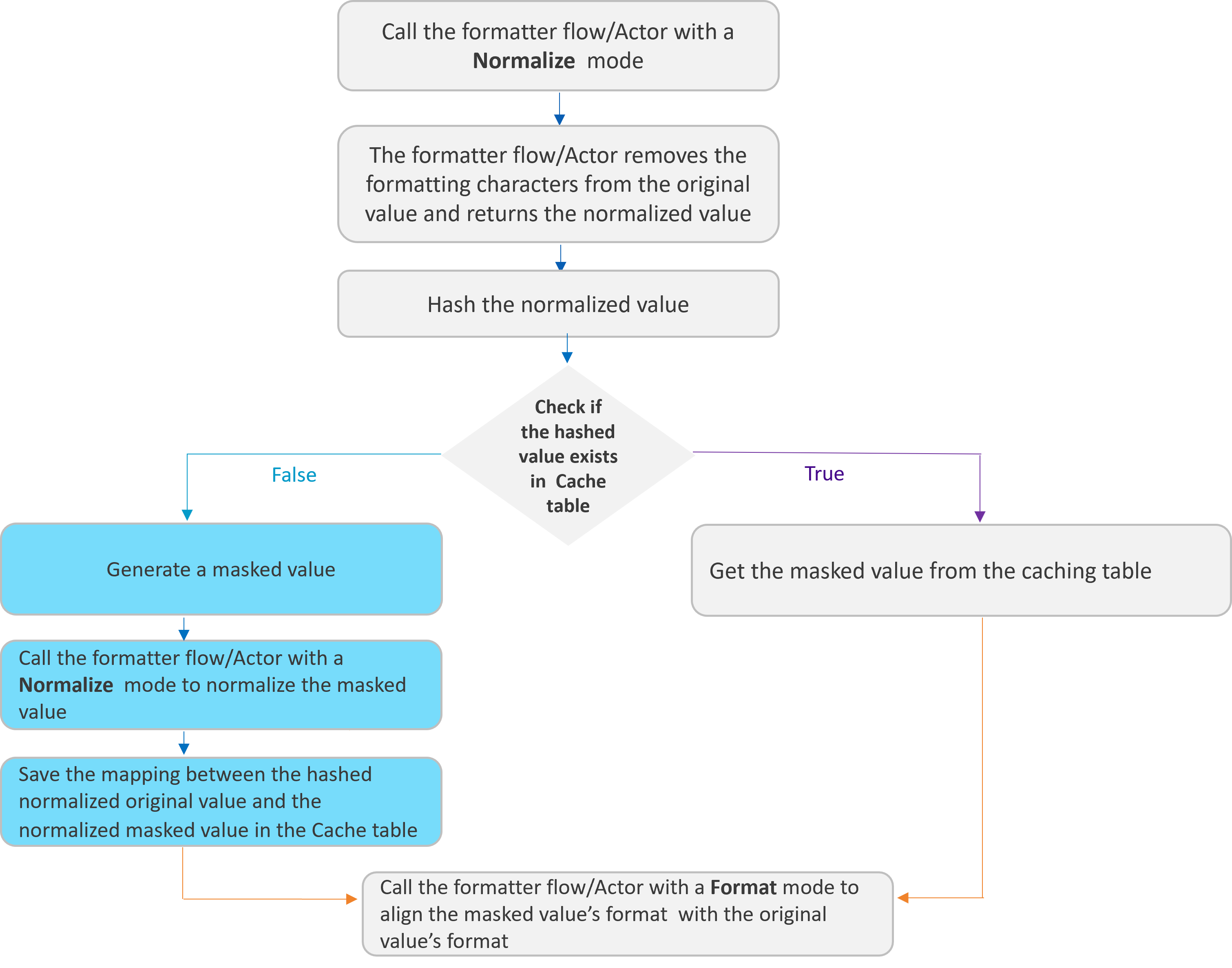
Click here for more information about the formatter flows and Actors.
K2view Masking Advantages
- The support of cross instances consistency, based on the hashed values.
- The original value is not used as an input for creating the random masked value, other than for formatting purposes.
- The MicroDB is created with the masked values.
- The usage of K2view's Masking mechanism (using SHA-512/256 algorithm).
- Multiple masking options enable maximal flexibility when masking the data.
De-Anonymization (Pseudonymization)
In some cases, there is a business need to retrieve the original value of the masked LUI. For example, a retrieval of a mailing address in order to contact the customer.
There are 2 recommended approaches to support de-anonymization and retrieve the original value of the masked field:
Keep the source Instance ID in Fabric and use it to retrieve the original data from the source system.
Keep the encrypted version (each instance is encrypted separately) of the original values in Fabric only, in addition to the anonymized values. Limit the access to the anonymized data. Only permitted users can access the original values.
Click here for more information about the LUI encryption.


Fabric Data Masking
Data Privacy laws require the ability to mask data by hiding the original values with a modified content. Fabric provides a field-level API to protect data that is classified as Personal Identifiable Information, sensitive personal data, or commercially sensitive data.
To ensure that the data is still valid for your data lifecycle management, the masked data will look real and appear consistent.
This capability can be used for conducting tests, implementing data transformations, or providing anonymized data to external 3rd parties via web services or queue messages.
Masking Flow
The masking of sensitive data can be done by either the LU Table Population Broadway Flow that runs during the LUI sync before saving the LUI in Fabric, or by using a Broadway flow to mask the LUI data before it is loaded to the target.
The masking process consists of 2 main parts:
Data generation - generating a random masked value for the masked field.
Data consistency - verifying that the same original value gets the same masked value.
Fabric supports 2 methods to keep the data consistency:
- Data consistency using table.
- Data consistency using seed.
The data consistency method is set based on the interface parameter of the Masking Actor: If the interface parameter is populated with SEED, the masking mechanism keeps the Data consistency using seed method.
Data Consistency Using Table
The mapping between the hashed original and masked values is kept in a caching table, which is defined under the k2masking schema.
The following diagram describes the sensitive data masking process, using an LUI sync:
The following diagram describes the sensitive data masking process before loading the data to the target:
Data Consistency Using Seed
This new method has been added in Fabric 8.2. and it ensures referential integrity without saving the mapping between the hashed original value and the masked value in the caching table. It can therefore lead to better performance, when compared to regular masking, as it does not need to access the DB. The mapping between the hashed original value and the masked value is not kept in the caching table, but rather in the Java Random method using a seed. A seed is like a starting point for generating random numbers, and it ensures consistency of the generated value.
If the Masking actor's interface input argument is populated with SEED, the masking Actor populates the seed with the caching key and sends it to the data generation Actor.
This is available only if the data generation Actor has a seed input argument, and it uses the Java Random method to get the masked value when the input seed is populated. All the built-in data generation Actors support data generation based on seed.
Notes:
In both data consistency methods, Fabric uses the SHA-512 or SHA-512/256 algorithms to hash the original value. Additionally, Fabric uses a dedicated master key to salt the original value before hashing it. The hashing is a one-way activity. The hashed value cannot be reversed back to the original value.
Click here for more information about the Fabric hashing mechanism.
The Data Consistency Using Seed does not keep the referential integrity when the masked value is taken from a dynamic list: If the seed is identical, the random function will bring the same index from the list. It checks the index of the returned value and not the value itself. We therefore recommend to use the Data Consistency Using Table method for keeping the referential integrity in this case.
For example, an MTable that contains a list of names is created at run-time. The 5th index is populated with 'Jonn' on the first run and 'Harry' on the second. If the first run gets 'John', the second run will get 'Harry' when running on the same seed as the first run. This happens because both names have the same index in this example.
The masked value is impacted not only by the seed, but also by the data generation parameters. For example, getting a random value between 0-100 returns a different result than when getting a random value between 0-200, even if they get the same seed value.
The Consistent and unique consistency mode does not support data consistency using seed. Instead, it relies on tables within the k2masking schema to ensure both data consistency and uniqueness of masked values.
Broadway Masking Actors
The masking process is executed by Broadway Actors that enable masking sensitive data before it is loaded into a target database or even into Fabric. The masking process contains the generation (manufacturing) of a random synthetic value that replaces the real value, and the caching of the hashed original value and the masked value in order to keep the referential integrity of the data. Starting from V7.1, Fabric separates data generation (manufacturing) from the hashing and caching capabilities. Broadway provides the following Actors:
- Various data generation Actors under the generators category to generate a random synthetic value. For example: RandomString, RandomNumber, Sequence…
- Masking Actor - this Actor can wrap any data generation Actor and add the hashing and caching capabilities on top of the data generation Actor.
- Broadway still keeps the existing masking Actors for backward compatibility reasons.
The masking Actors use the Fabric hashing utility to hash the original value, and to save the mapping of the hashed and the masked values to the cache table.
Click here to read how to use Fabric's masking Broadway Actors.
Click here to read more about the Fabric hashing mechanism.
Customized Masking Logic
K2view enables users to create their own masking functions:
- The MaskingLuFunction Broadway Actor can be used to call a customized function (a shared function or an LU's function) - to mask the required field.
- The MaskingInnerFlow Broadway Actor can be used to call a customized Broadway flow or an Actor - to mask the required field.
- Fabric 7.1 provides the general Masking Actor that enables running either a customized inner flow or an Actor - to mask a required field.
Click here for more information about the data generators implementation.
The use of MaskingLuFunction, MaskingInnerFlow or Masking Actors guarantees the usage of the masking mechanism, including SHA-512/256 hashing and caching capabilities. The user does not need to handle them by their customized function.
Masking Actors Properties
Interface
- The interface to be used to cache the masked values. If the interface is populated with SEED, the Masking Actor populates the seed with the caching key and sends it to the data generation Actor.
Target Value Uniqueness
- The user can decide whether the masked value is unique per original value (hashed value) or if it can be used for more than one original value. For example, a masked SSN must be unique, but a masked Family Name can be the masked value of different original values.
Cache with Expiration Date
- Each cached link of a hashed value to a masked value can have a TTL (Time To Live). This link will expire once the TTL has been reached, and the original value will be masked again.
Caching Key - Caching Level Parameters
- The caching of the masked values can be saved on different levels, based on the user’s input. Each one of the following parameters can be enabled or disabled from being a part of the Caching key:
- Instance ID
- Environment
- Execution ID
Format Preserving Masking
Format-preserving masking, introduced in Fabric 8.0, provides a solution for maintaining consistent data masking across multiple fields while preserving their original formatting patterns. It addresses scenarios where the same underlying value appears in multiple fields with different formatting patterns.
An optional parameter has been added to the Masking Actor - formatter - to enable format-preserving masking. This parameter can be set with either a formatter flow or an Actor in order to preserve the original format in the masked value and to set the same masked values to all fields that have the same normalized (’naked‘) value, although each field has a different format.
Example:
- The phone number exists in multiple fields in the data source in different formats: +1 (254) 455 5666, +1(254)4555666, +1 (254)-455-5666.
- All these fields must get the same masked value (as they correspond to a single phone number), but the format needs to be different for each field in order to match its original format.
|
Original Value |
Masked Value |
|
+1 (254) 455 5666 |
+1 (254) 430 8992 |
|
+1(254)4555666 |
+1(254)4308992 |
|
+1 (254)-455-5666 |
+1 (254)-430-8992 |
The following diagram describes how the Masking Actor uses the formatter for preserving the original format in the masked value:
Click here for more information about the formatter flows and Actors.
K2view Masking Advantages
- The support of cross instances consistency, based on the hashed values.
- The original value is not used as an input for creating the random masked value, other than for formatting purposes.
- The MicroDB is created with the masked values.
- The usage of K2view's Masking mechanism (using SHA-512/256 algorithm).
- Multiple masking options enable maximal flexibility when masking the data.
De-Anonymization (Pseudonymization)
In some cases, there is a business need to retrieve the original value of the masked LUI. For example, a retrieval of a mailing address in order to contact the customer.
There are 2 recommended approaches to support de-anonymization and retrieve the original value of the masked field:
Keep the source Instance ID in Fabric and use it to retrieve the original data from the source system.
Keep the encrypted version (each instance is encrypted separately) of the original values in Fabric only, in addition to the anonymized values. Limit the access to the anonymized data. Only permitted users can access the original values.
Click here for more information about the LUI encryption.
